
数据架构的世界,总是热闹非凡。
从最早的数据仓库、大数据、到近年的数据湖、湖仓一体、数据中台,再到最近几年风头正劲的数据编织与数据即服务,每隔三四年,就有一个新名词横空出世。厂商热推、圈内热议,仿佛不上这趟车就要落伍。但很多企业用了才发现:听起来高大上,用起来却水土不服。
那么,这些名词之间到底是什么关系?它们是技术演进,还是概念叠加?哪些是互相替代,哪些可以协同共存?东方金信将带你从多个关键维度梳理这些主流数据架构体系,厘清它们的来源、定义、概念核心、优势、劣势、适用场景与未来趋势等,帮你真正看懂数据架构背后的逻辑,不再被术语牵着鼻子走,同时可按照需求选择适合自己的数据架构。
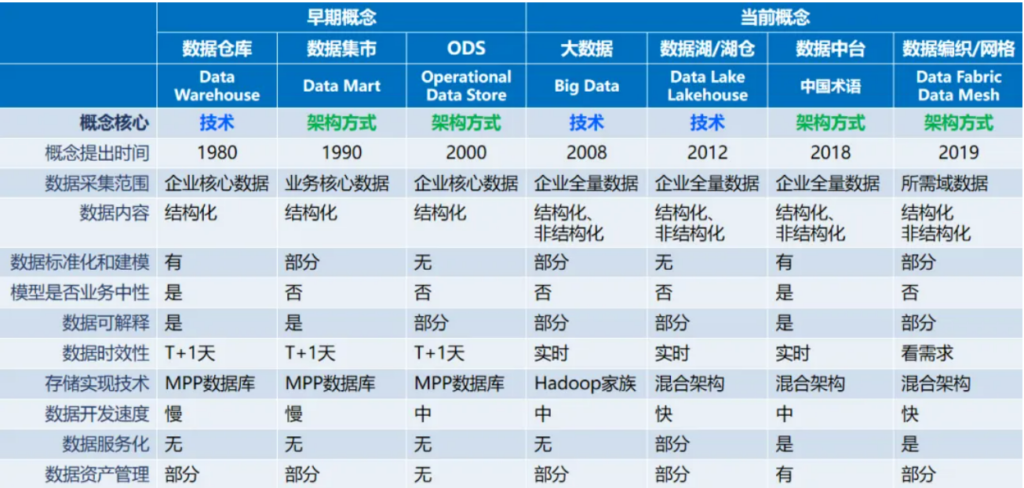
图1:数据架构概念对比表

在所有数据架构体系中,数据仓库是最早提出、也最为成熟的体系。它诞生于20世纪90年代,由 Inmon 和 Kimball 两位数据架构大师分别提出了“企业级数仓”与“维度建模”的理论框架,至今仍是企业数据体系的基石。
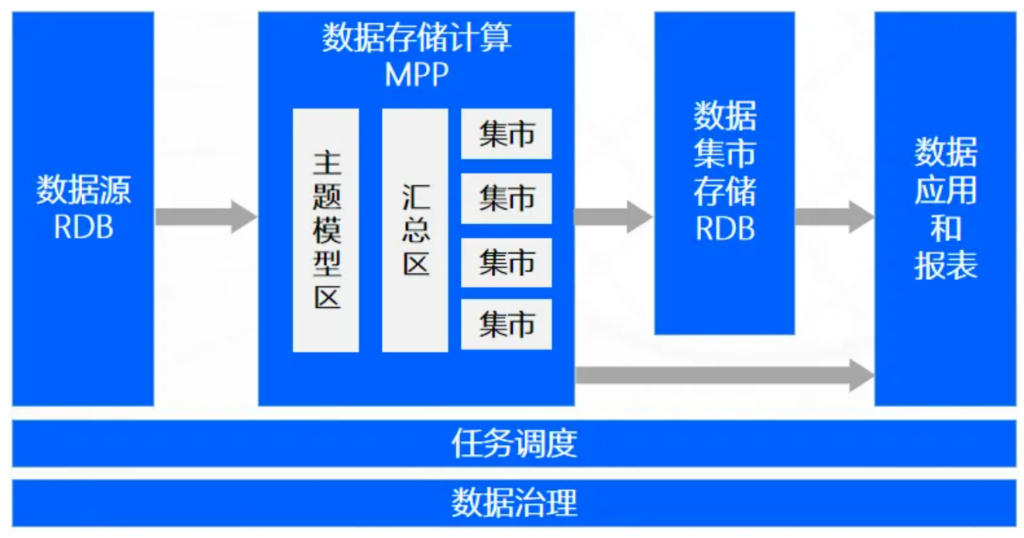
图2:数据仓库架构图
数据仓库的定义是面向主题的(subject oriented)、集成的(integrate)、相对稳定的(non-volatile)、反映历史变化(time variant)的数据集合,用于支持管理决策。典型特征:以范式存储的历史拉链表。
数据仓库的诞生是当时出现了新技术——MPP(大规模并行处理)数据库,使得数据集中存储和分析成为可能。但数据仓库不是只能用MPP数据库实现,只要是构建了稳定的、中性的主题数据模型,用Hadoop家族甚至单机数据库也一样可以构建数据仓库。
✅ 优势:中性的、稳定的、高质量、标准化的数据模型;可以进行复杂加工;包含历史变化数据。
❌ 劣势:数据加工速度慢;需求响应慢;没有流计算能力;MPP数据存储容量有上限(小于500节点);非结构化和日志数据通常不存储。

由于数仓需要构建与源系统结构截然不同的主题数据模型,因此造成一定的复杂性和加工慢的问题,因此为了满足业务更快的加工数据需求,诞生了操作型数据存储(ODS),即直接构建与源系统保持一致的区域,又叫镜像层。从该区域直接加工数据集市所需的数据。
ODS是一种数据架构方式,不是新技术驱动概念,ODS也是Bill Inmon提出,并可以构建在MPP或Hadoop大数据家族中。早期由于MPP数据库的存储昂贵,因此ODS和数据仓库出现过二选一的争论,随着数据存储单价越来越低,目前绝大多数架构中,通常二者都会同时构建。注意,现在有部分技术人员分不清数据仓库和ODS,也称ODS为数据仓库,这个要加以区分。
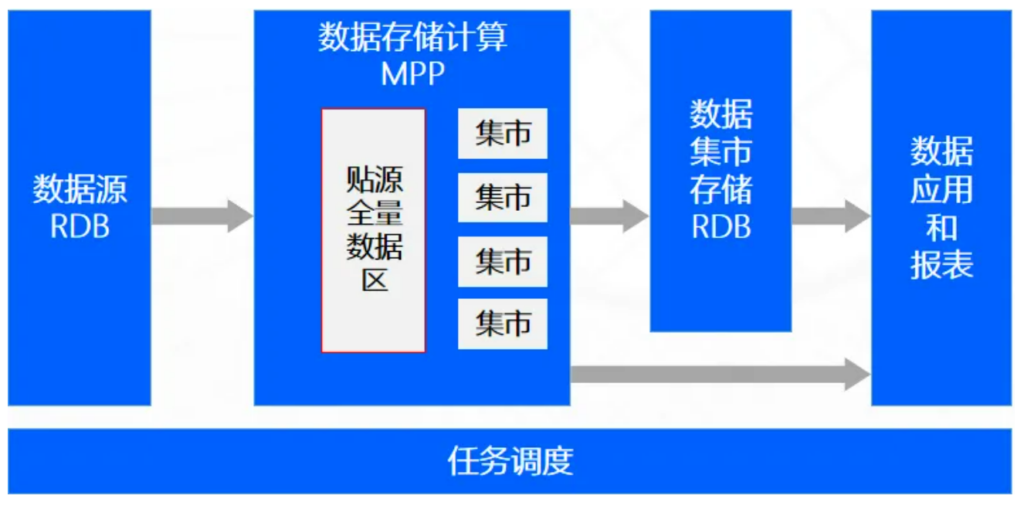
图3:操作型数据存储架构图
✅ 优势:比数仓加工速度快;需求响应快;用户容易理解。
❌ 劣势:集市层有冗余加工;数据没有标准化;非结构化和日志不采集;数据治理难。

如果说数据仓库强调的是规范的高质量数据,那么大数据代表的就是“海纳百川 + 快速处理 + 灵活探索”。大数据的崛起,是源于互联网时代数据类型与数据量的爆炸性增长。大数据最早是一个技术范畴,强调处理海量、多样、快速变化的数据(即 3V:Volume、Variety、Velocity),其代表性技术产品很多,包括:Hadoop、Spark、HBase、Kafka等,但是大数据这个词汇过于宽泛,没有统一架构、也没有唯一产品形态,因此Gartner在2014年后逐渐弱化大数据这个术语,以更精确的概念代替。
数据湖这一术语,是用来描述将数据以文件方式原始地存储在Hadoop中。它的提出代表先存后治的数据管理方式。数据湖和大数据通常是指一个概念。
由于大数据的海量(Volume)和高速(Velocity)的数据处理很难一起实现,因此通常采用批量数据和流数据两条路径分开的处理方式,这种模式又被称为Lambda架构(数据仓库和流计算也可以组合成Lambda架构)。不过近些年随着技术的进步,双路处理的复杂性被质疑,新一代架构(如Kappa、实时数仓等)开始尝试“批流统一”。
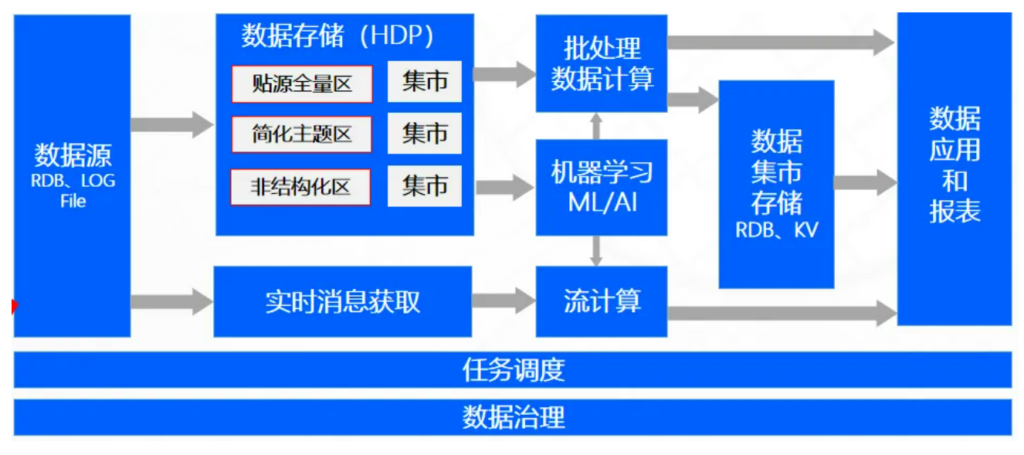
图4:大数据/数据湖架构图
✅ 优势:存储容量大;存储类型丰富;有实时数据加工能力。
❌ 劣势:难以做复杂数据加工;集市层有冗余加工和存储;技术栈复杂;数据治理难。

数据湖落地后,很多企业发现它并不适合直接承担数据分析和建模任务,于是又搭建了一座传统数据仓库——这一“湖边再建仓”的架构,被称为湖仓分离架构,又被形象地称为湖边小屋。湖仓分离的架构思路很简单:将原始数据沉淀在数据湖中,再通过抽取加工,加载到一个结构化的数据仓库中进行建模分析。
湖仓分离架构是目前大多数企业采用的架构。
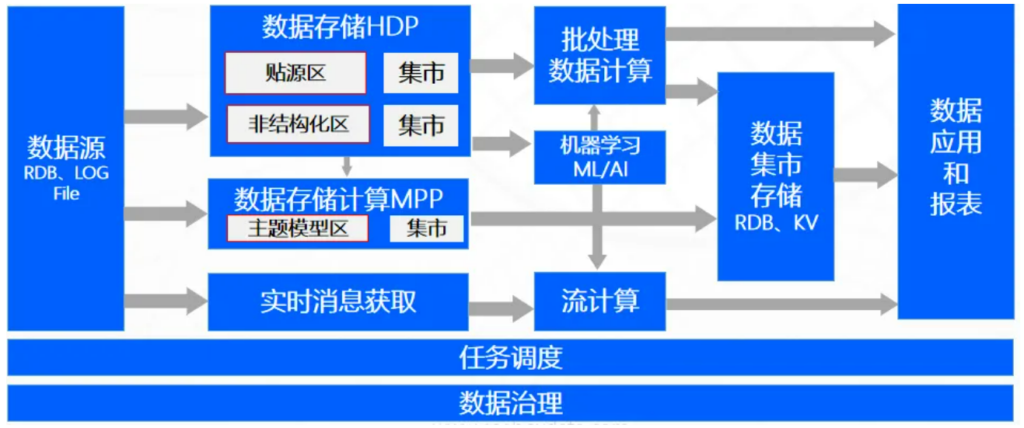
图5:湖仓分离/湖边小屋架构图
✅ 优势:可复杂数据加工、存储容量大、存储类型丰富。
❌ 劣势:数据链路长、架构复杂、数据冗余、开发运维成本高。

数据湖太乱,数据仓库太麻烦,湖仓分离又难维护——于是,“湖仓一体”方案顺势而起。湖仓一体(Lakehouse)是将数据湖与数据仓库的优势融合为一体的架构设计,它试图做到像数据湖那样 支持海量、多样、低成本的数据存储;又能像数据仓库那样 具备强治理、高性能、支持分析建模能力。
湖仓一体的概念也依赖于以下技术突破:即在湖上实现的ACID能力,如 Delta Lake、Apache Hudi、Apache Iceberg等。不过,湖仓一体不是简单的“湖+仓”拼接,而是对底层存储、元数据、查询引擎的深度重构。只有在治理、建模、权限、安全等多方面都做到了融合,才能真正称得上“湖仓一体”,否则只是“湖仓共存”而已。
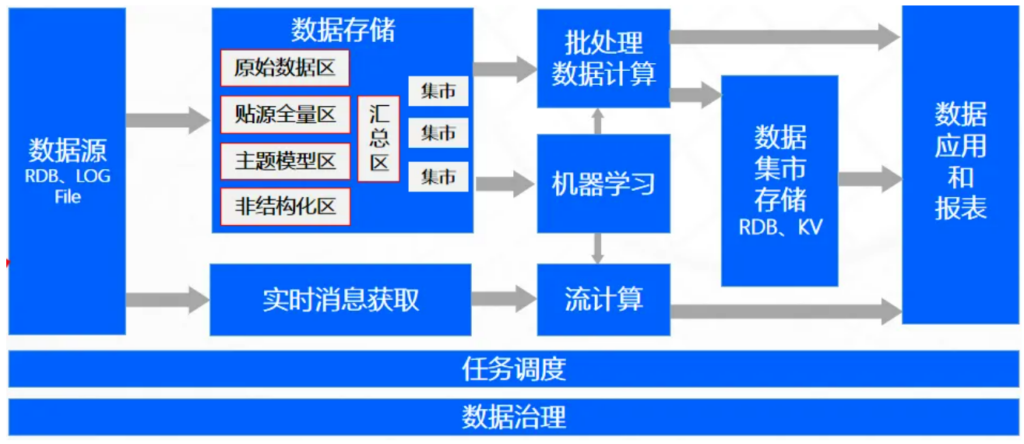
图6:湖仓一体架构图
✅ 优势:可复杂数据加工、数据统一存储计算、架构简单。
❌ 劣势:架构和技术仍不成熟,技术门槛高、缺少最佳实践。

数据中台起源于阿里巴巴在2015年左右提出的“中台战略”,其核心理念是:将企业内部重复建设、重复提数、重复加工的数据能力进行统一抽象、集中建设、共享复用,从而提高整体数据资源使用效率与响应业务的速度。
数据中台概念更多的是一种数据共享愿景,本身并没有一个明确的技术架构,不论是用数据仓库、数据湖均可以实现数据中台。但是,经常被提到数据服务网关其实并不是数据中台概念的核心。
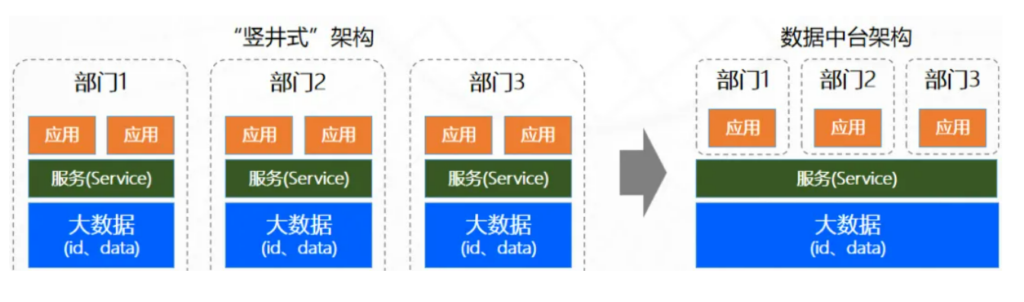
图7:数据中台理念图
✅ 优势:打破数据孤岛、沉淀企业数据资产、统一对外服务。
❌ 劣势:无技术架构、概念不统一、业务感受价值低。

无论是数据仓库、数据湖,还是数据中台,它们的目标都是统一:统一存储、统一加工、统一服务、统一治理。但是在超大型企业中,部门(或子公司)业务差异大、系统复杂、历史包袱重、组织壁垒强,因此在超大型企业进行统一的数据存储处理的理想很难实现。于是,数据编织(Data Fabric)诞生了——它不是强行统一,而是“以编织取代改造”。
数据编织是一种分布式异构环境下的数据智能访问与治理架构。它不强求统一重构,而是像织毛衣一样,通过元数据驱动和智能推荐,将企业中分散的数据系统编织成一个“虚拟整体”。
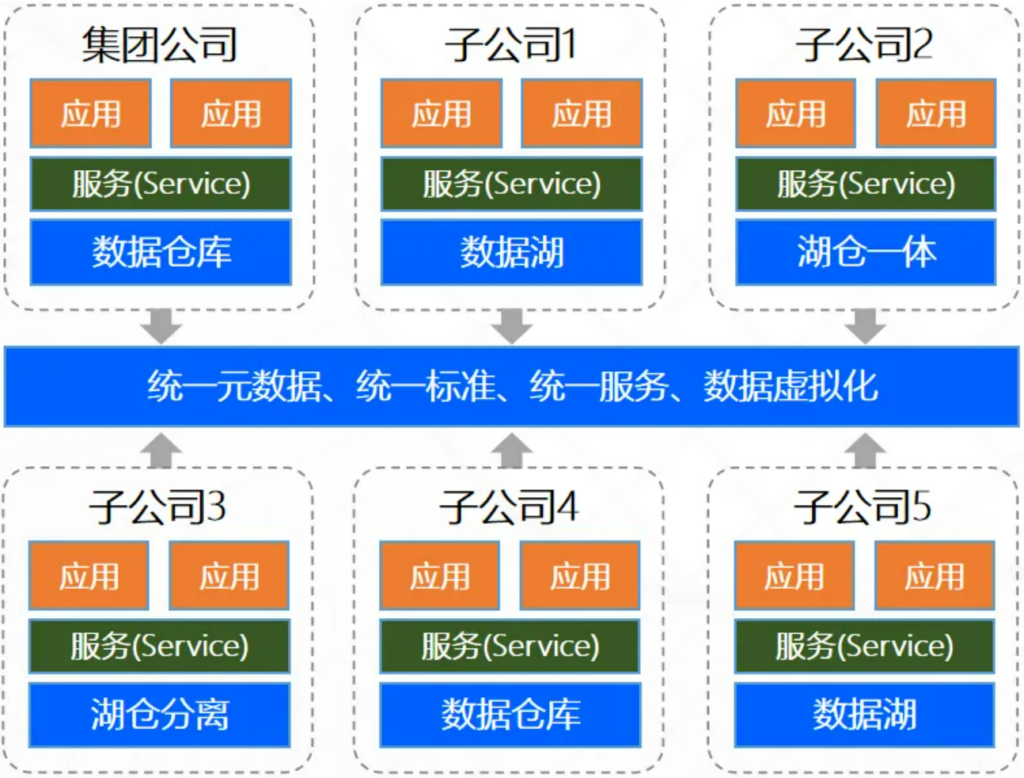
图8:数据编织架构图
但是,要注意的是,很多企业在落地数据编织时,容易误解其“分布式连接”理念,把它当作逃避数据治理、继续烟囱建设的借口,最后沦为“新的数据孤岛”。

数据网格理念在 2019 年由ThoughtWorks首次提出,其主张彻底颠覆传统中央数据平台式,转向数据即产品(Data as a Product)和跨域自治的组织型数据架构。它借鉴了微服务架构(特别是 Service Mesh)的理念。
但是数据网格的提出人以处理程序的思想处理数据,这是对数据理解的不到位,程序喜分散,数据喜聚合,程序可以微服务化、自治化;而数据一旦分散,就面临一致性、血缘、质量、标准、安全的灾难。因此,数据网格并没有良好的落地方案,Gartner在2022年已经宣告其淘汰。

我们看到,从数据仓库到数据湖,数据中台、湖仓一体、数据编织,数据架构的每一次变化,既有技术推动,也有业务驱动,更有组织演进的深层动因。看似层出不穷的新名词,其实都在回应企业三个永恒的问题:
- 数据该怎么存?(基础设施层)
- 数据怎么好用?(数据治理层)
- 数据如何形成价值?(数据应用层)
东方金信设计的现代企业数据堆栈架构(如下图),兼顾现状与未来,融合数据仓库、数据湖、湖仓一体、中台与网格理念,构建灵活、可演进、可治理的数据底座,全面满足政企行业在数智化转型中的多样化需求。
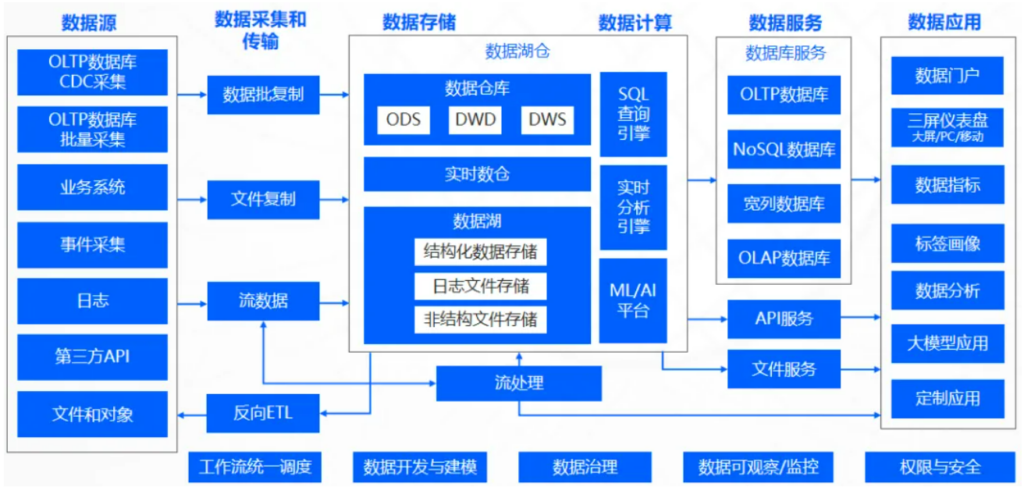
图9:东方金信现代企业数据堆栈架构图
作为国内领先的数据基础软件与架构服务提供商,东方金信不仅提供自研的MPP数据库、大数据平台、数据湖、数据治理等核心产品,也长期为大型客户提供数据中台、湖仓一体、数据编织等架构落地咨询与规划服务,帮助企业实现从“数据孤岛”走向“数据能力共享”的转型升级。